














To Scrape or Not To Scrape
April 20, 2023
We stand on the shoulders of giants every time we unveil a breakthrough invention. That’s well established. From Newton to NASA, etc. etc.
But when you dig into this concept, sometimes you need to turn down the volume on the triumphant orchestral soundtrack.
Facebook and Twitter stood on the shoulders of legacy media in the 2010s. They stockpiled all the ad revenue which led to the crumbling of trust and revenue for fact-checked media.
When pushed, Facebook’s response to profit sharing was, and continues to be, “No More News”
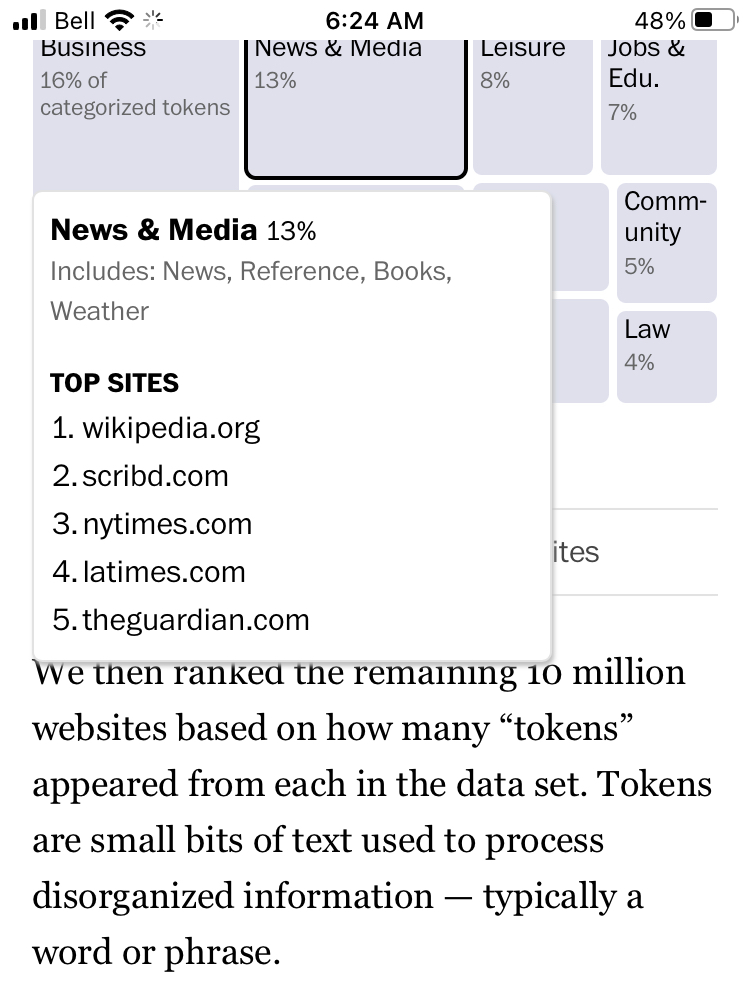
A new Washington Post investigation goes under the hood of generative AI’s LLMs and shows, once again, this latest tech advance relies heavily on The New York Times, The LA Times and The Guardian (all subscription businesses) for its firepower. Wikipedia is at the top of the Scaping List, but that’s a separate story. Canadians, the Toronto Star is number 98 on the list of Top 100 scraped sites.
There’s something deja-vooey about all of this. Will good working partnerships with tech continue to elude us? Heck, we haven’t even found a fair business model for content creators and social media companies, and we’re already moving out of that era.
I hope the coffee is extra strong in legislatures around the world. As citizens, let’s stay committed to trying to understand what’s at stake for everyone, even as we integrate these tools into our workflows and lives.
In the meantime, the danceathon between permission and forgiveness raves on.











Leave a Reply